


A Single API Error Stops the World
It’s 10:05 a.m. on a perfectly normal Tuesday. A customer tries to check out on an e-commerce app. The payment hangs. They try again, still nothing.
By 10:06, social media is full of “checkout not working” screenshots.
By 10:15, support teams are drowning in complaints.
By noon, revenue dashboards are dropping, engineering is scrambling, and the brand is taking damage in real time.
The trigger?
A single API error is buried somewhere in the payment flow.
When Digital Infrastructure Breaks in Public
This kind of moment happens more often than most leaders realize.
- A Stripe API outage freezes payments across dozens of retailers.
- Discord hits an API 400 error, or the notorious 418 Teapot, and millions of users can’t log in.
- The T-Mobile API exposure, which leaked data from 37 million accounts, quietly unfolded for weeks before anyone noticed.
None of these incidents began with dramatic cyberattacks. They started with small, quiet technical failures that spiraled into public business failures.
Why This Isn’t a “Developer Problem”
API-related outages and breaches now cost organizations billions annually. More than 90% of companies reported at least one API incident in the past 12 months (estimated).
Those aren’t IT numbers. Those are business numbers, tied directly to lost revenue, lost trust, and lost time.
One error message. Thousands of failed transactions. Millions in trust lost.
The lesson is clear: API errors are not backend clutter. They’re signals, early warnings that something in the digital ecosystem isn’t aligned.
What This Guide Will Reveal
We will explore what API errors really mean, why they happen, what they cost, and how modern organizations turn them from chaotic noise into strategic insight.
But before we can think of them as strategy signals, we need to understand what an API error actually represents beneath the surface.
Beneath the Code: What API Errors Really Represent

APIs are how systems talk. Each request is a sentence. Each response is an answer.
When the conversation breaks down, you get an API error: the digital equivalent of two teams using the same language but with different dialects.
Sometimes the misunderstanding is minor. Other times, it’s the spark that ignites a larger issue.
A wrong parameter? Fixable.
A missing permission check on a sensitive endpoint? That’s how incidents like the Optus breach exposed personal data for millions.
A Simple Picture: The Supply Line
Imagine your APIs as the supply lines of a modern business. An error is a break in that line:
- Mild and contained, like a small leak, or
- Severe and cascading, like a ruptured pipe affecting everything connected to it.
A single timeout may be harmless. A chain of timeouts across microservices? That’s a system under stress, not a one-off glitch.
API Errors Are Signals, Not Events
Every API error has meaning. It reflects something more profound:
- A design mismatch,
- A permission gap,
- An overloaded dependency,
- Or a timing failure between systems.
When errors repeat, they’re telling you a story. Customers feel the pain immediately. Attackers study the patterns. But organizations often only see the symptom, not the signal.
Also Read:
Why This Understanding Matters
A lone API timeout in a banking app may not worry anyone. But repeated timeouts across vital workflows point to something structural: a weakening of coordination and trust between the core services that run the business.
And like every meaningful signal, it’s impossible to decode without understanding what actually causes it.
The Triggers: Why API Errors Happen (And What They Reveal)
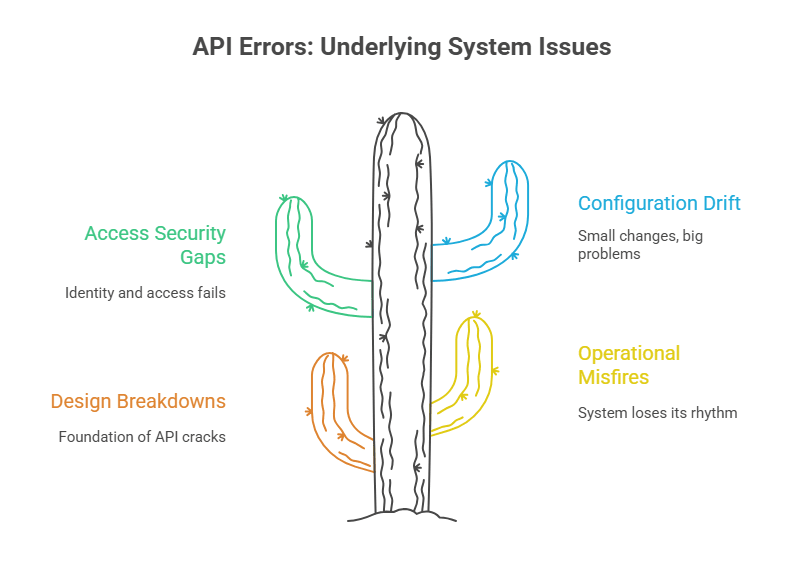
API errors rarely appear out of nowhere. They usually emerge from small misalignments that grow into visible failures: a design decision made months ago, a dependency running slower than usual, a permission misconfigured during a routine update. These aren’t just “bugs”. They’re signals of deeper gaps in coordination across teams, systems, and decisions.
Understanding these triggers helps leaders see API errors for what they truly are: early warnings about fragility, governance, and alignment inside the digital ecosystem.
1. Design and Logic Breakdowns: When the Foundation Cracks
Some API errors begin long before anyone makes a request. They’re born in design rooms, version histories, and mismatched assumptions across teams.
Common triggers include:
- Poor version control leading to breaking changes nobody planned for
- Schema mismatches, where one service expects JSON in one format and another delivers something different
- Dependency errors, where a single failing database or service triggers error storms across multiple APIs
- Ambiguous or outdated documentation, causing teams to call the wrong endpoints or use incompatible payloads
These issues reflect fragility: minor weaknesses beneath the surface that stay quiet until traffic spikes or new features roll out.
A well-known example happened with PayPal: an unannounced API version change during a busy shopping period caused merchants to lose transactions. Nothing “hacked” PayPal. Coordination failed, and design drift rippled into revenue loss.
2. Operational Misfires: When the System Loses Rhythm
Even perfectly designed APIs can break when the underlying infrastructure is under strain or misaligned. These issues show up in the real world fast.
Triggers include:
- Server overload, where CPU or memory maxes out, and APIs respond with 5xx failures
- Network congestion, which often leads to API timeout errors or intermittent API connection errors
- Third-party downtime, where partner APIs slow down or fail, triggering API call errors across dependent workflows
- Faulty caching, causing stale or missing data that breaks logic down the line
These are problems of coordination. Each part of the system might work fine on its own, but together they misfire, and every dependent service pays the price.
Anyone who has used Xfinity during peak hours has likely seen the “what is api timeout error on Xfinity” trend in support forums. That’s not a user mistake; it’s a network under stress creating unpredictable timeout failures.
In microservice architectures, a single timeout can cause cascading failures. One slow service delays another, which delays another, until the entire chain slows or fails. What begins as a minor api call error becomes a full-scale outage.
3. Access and Security Gaps: When Identity Fails
A large portion of API errors comes from identity and access issues: mistakes that are invisible until something breaks.
Common triggers include:
- Expired tokens, causing every request to fail authentication
- Incorrect permissions, where role-based access controls (RBAC) block or expose the wrong data
- Misconfigured OAuth/OpenID flows, causing users to be mistakenly denied access or, worse, granted persistent access when they shouldn’t have it
These issues represent failures in governance – the rules and policies that protect APIs.
And the stakes are high: misconfigured or exposed APIs are a leading cause of modern data breaches. These aren’t attackers breaking in. These are doors left unlocked by accident.
4. Configuration Drift: When Small Changes Create Big Problems
Configuration drift is one of the silent killers of API reliability. It happens slowly, silently, and usually at the worst possible time.
Key causes include:
- Human error during environment setup (wrong endpoint, missing variable, outdated URL)
- Unapplied updates, such as outdated libraries, unpatched services, or old API versions, are still lingering in production.
- Inconsistent environments, where staging, testing, and production behave differently
This is a problem of vigilance. APIs evolve constantly, and minor inconsistencies accumulate until something eventually breaks.
Research shows that a significant majority of downtime incidents in complex API environments can be traced back to config drift and missing validation.
The Real Pattern Behind All These Triggers
While each cause looks technical on the surface, nearly all API errors reflect a more profound truth:
API errors aren’t just code issues. There are coordination issues.
Teams, services, versions, dependencies, and rules fall out of sync. And when they do, the API layer becomes the first place where those fractures become visible.
And these coordination gaps show up in recognizable error families that leaders can learn to read like a dashboard.
The Common Types: Learning to Read the Error Language
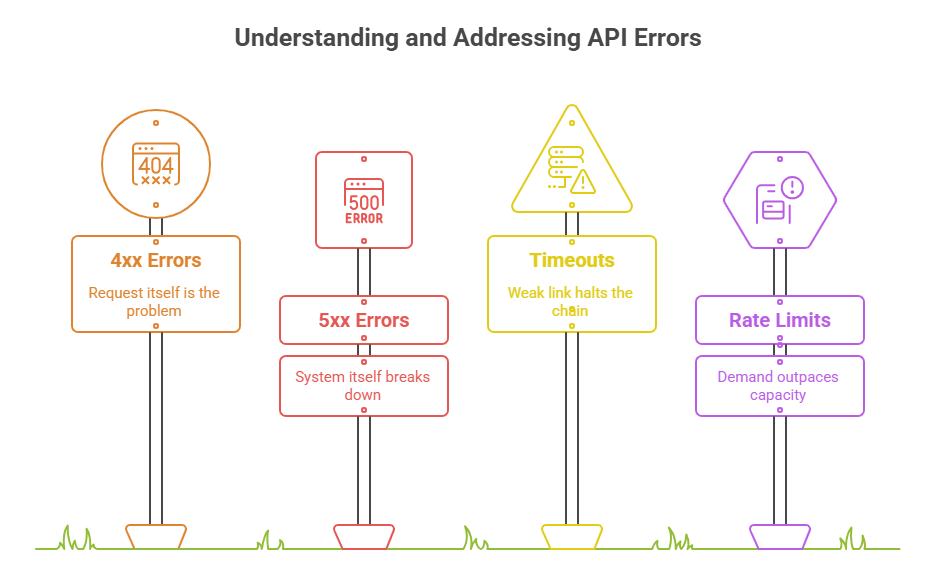
API errors may feel chaotic when they appear in logs or dashboards, but they actually fall into clear, predictable families. Once you know how to read them, these codes act like a health report for your digital ecosystem, showing whether the stress is coming from users, systems, dependencies, or demand spikes.
Below are the core categories every leader should recognize.
1. 4xx Errors: When the Request Itself Is the Problem
These are client-side issues. The API receives a request it can’t process: wrong inputs, expired tokens, missing permissions, or simply asking for something that doesn’t exist.
Common examples include:
- 400 – Bad Request
- 401 – Unauthorized
- 403 – Forbidden
- 404 – Not Found
Think of these as a polite: “You asked wrong”.
In real life:
- A mobile app with outdated tokens can trigger millions of 401 failures.
- Misconfigured frontend logic can cause 400 storms, something platforms like Discord and Ticketmaster have faced at scale.
These errors often stem from validation issues, stale sessions, or incorrect assumptions about how users interact with your system.
2. 5xx Errors: When the System Itself Breaks Down
5xx errors signal failures inside the server or backend application. These typically indicate resource exhaustion, code exceptions, database failures, or infrastructure outages.
Common examples:
- 500 – Internal Server Error
- 502 – Bad Gateway
- 503 – Service Unavailable
- 504 – Gateway Timeout
This family is the system quietly saying, “I can’t handle this right now.
Business reality:
- Commerce platforms see 503 errors when payment processors go offline.
- AWS, Stripe, and other cloud providers frequently publish incident reports centered around 5xx spikes caused by backend overload or maintenance.
5xx errors are operational red flags. They tell you the system is under strain or misconfigured.
3. Timeouts and Dependency Failures: When One Weak Link Halts the Chain
A timeout occurs when a service doesn’t respond within a specified time. In distributed systems, this often exposes hidden dependencies or network issues.
Examples you’ve probably seen:
- API timeout error when a database query takes too long
- API connection error when a downstream partner is unavailable
- The familiar “API timeout error on Xfinity” during network congestion
Timeouts are often the most revealing signals, because they expose the health of the entire chain, not just one service.
A single stuck dependency can trigger cascading failures across microservices. What looks like a small API call error can turn into a system-wide slowdown in minutes.
4. Rate Limits and Throttling: When Demand Outpaces Capacity
Rate limiting errors occur when the number of requests exceeds what the API is designed (or allowed) to handle.
Typical code:
- 429 – Too Many Requests
These errors signal abnormal or unexpected demand. Sometimes it’s legitimate spikes (ticket sales, logins), sometimes bots or abuse.
A well-known recent example: Developers encountered the Gemini API Error 429 when traffic surged beyond its quota, forcing teams to optimize load or request higher limits.
Understanding the Signal Behind the Code
Each error family points to a different kind of stress:
- 4xx errors → user problems, bad inputs, or broken client logic
- 5xx errors → backend failures, resource strain, or code issues
- Timeouts & dependency errors → fragile integrations, slow networks, or hidden bottlenecks
- Rate limits → capacity constraints or abnormal traffic patterns
For executives, these aren’t technical distinctions. They indicate where the business needs attention: the user journey, the backend foundation, the integration ecosystem, or traffic governance.
Handling These Errors the Right Way
Each error category also demands its own approach.
- 4xx issues require robust input validation, clear user guidance, and effective contract management across teams.
- 5xx issues need fault-tolerant retries, graceful fallbacks, and better backend observability.
- Timeout chains demand load testing, dependency health checks, and caching discipline.
- Rate limits require quota planning and exponential backoff strategies.
The best engineering teams document API error-handling patterns early, ensuring REST API error-handling best practices are consistent across all microservices. Over time, this consistency becomes a significant reliability multiplier.
Platform-Specific API Errors: What They Mean
Modern teams interact with AI platforms, cloud services, and external integrations daily. Each comes with its own error language, and learning that language helps benchmark resilience across tools.
- Claude API Error 529/400
Usually indicates temporary capacity overload (529) or malformed input (400). Often resolved through retry logic or better request formatting. - Gemini API Error 429
Triggered by rate limiting. Shows up during usage spikes, rapid prototyping, or traffic bursts during events. - AWS API Error
Commonly linked to IAM permission issues or service unavailability. These errors often reveal gaps in access governance or redundancy planning. - Anthropic API Error 529
Signals high load or capacity limits. Best practice is to retry with exponential backoff and monitor the platform status.
These examples highlight how API error handling varies across environments. Recognizing these patterns gives engineering leaders a more straightforward way to evaluate the reliability of cloud, AI, and SaaS solutions before they become critical dependencies.
The Ripple Effect: What API Errors Actually Cost Your Business

API errors don’t just break workflows. They break revenue streams, customer trust, security posture, and an organization’s ability to innovate. Their actual cost is rarely visible in the moment, but you feel it in the hours, days, and even quarters that follow.
APIs are invisible until they fail. And by then, it’s too late.
1. Revenue Impact: When Transactions Disappear in the Dark
Even a few minutes of API instability can drain millions from high-volume businesses.
- Financial services firms lose an estimated $37 million annually due to API downtime.
- Industry-wide, API-related failures cost more than $90 billion each year.
- A 0.1% loss in uptime equals 9 hours of downtime per year, enough to derail peak shopping windows for major retailers.
When Ticketmaster hits an api error 400 during a high-demand sale, the revenue impact is immediate and public. When PayPal APIs falter, every unprocessed transaction becomes a lost opportunity.
This is why many enterprises now track api error rate as a core business KPI: because every spike reflects a drop in conversions, purchases, and completed workflows.
2. Trust Impact: When Friction Becomes Reputation Damage
A surprising truth: 32% of users abandon an app after experiencing just one error.
People forgive slow pages, but not failures. A broken login or stalled checkout is enough to make them uninstall, switch providers, or post a frustrated review.
Real examples appear every week:
- A Discord API error 400 or the quirky 418 freezes millions of sessions, triggering social backlash.
- The default API error on Hotstar/Disney+ during a major match causes a flood of cancellations and angry tweets.
- A British Airways API error during the booking window leaves customers stranded in the purchasing flow.
Trust takes months to build and seconds (or one failed request) to erode.
3. Security Impact: When Errors Become a Map for Attackers
Every error message reveals something. Sometimes too much.
Attackers actively watch error patterns to identify:
- Authentication weaknesses,
- Misconfigured permissions,
- Sensitive endpoints leaking clues,
- And overloaded services are ripe for exploitation.
A predictable error spike, especially in identity flows, becomes reconnaissance data: the first step in a targeted attack.
A PayPal API error during authentication, or a 403 flood in an extensive application, often signals misalignment that attackers will test.
To secure your application against these, read:
- Web API Authentication and Authorization: Step-by-Step Guide
- API Security in Action PDF: The Guided Workbook Every CISO Needs in 2026
- NIST API Security Best Practices: The Complete 2026 Guide
Errors aren’t just technical noise. They are intelligent.
4. Operational Drag: When Teams Are Forced Into Firefighting Mode
High error rates shift entire organizations into reactive mode. DevOps stops improving systems and starts putting out fires. Product teams delay releases. Support queues balloon. Leadership loses visibility.
Persistent timeouts or recurring 5xx errors can lock teams into cycles of:
- Emergency root cause analysis,
- Cross-team war rooms,
- Temporary patches,
- And rushed fixes that later create new issues.
All of this drains innovation, not just time. The more teams fight error fires, the less they build new value. Modern competitors win simply by avoiding this cycle.
The Bigger Insight
API errors aren’t technical nuisances. They’re business disruptors.
Revenue drops, trust fractures. Security weakens. Innovation slows.
And yet, many organizations still miss the early warning signs. Not because the signals aren’t there, but because the tools watching them aren’t designed to understand them.
If the impact is so significant, why do so many companies still miss the signs? Because most are monitoring for uptime, not understanding.
The Visibility Gap: Why Traditional Monitoring Keeps You in the Dark
Most dashboards glow green even while customers are stuck. This is the core problem with traditional monitoring. It tracks the surface, not the story.
A system can return 200 OK while business logic fails silently beneath it. Uptime shows the lights are on; it doesn’t prove anyone’s actually home.
1. Green Dashboards, Broken Experiences
Legacy tools focus on:
- Uptime,
- Latency,
- CPU load,
- Simple alerts,
But none of these metrics tells you whether the business process behind the API is functioning.
Teams often experience “phantom green” – everything looks fine operationally, yet support tickets are skyrocketing.
A payment API returning 200 OK but delivering incomplete data is still breaking the transaction flow. A login API with incorrect token logic might “work” while quietly denying thousands of legitimate users.
Uptime isn’t health. Availability isn’t success.
2. The Blind Spots That Hide Real Risk

Traditional monitoring tools miss the deeper issues that actually affect customers and security.
Business Logic Errors
APIs returning wrong totals, incomplete data, or incorrect decisions are all invisible to uptime checks.
Uncorrelated Logs
Distributed architectures scatter information across services. Without correlation, errors that are obviously connected appear unrelated.
No Security Context
Error spikes often align with suspicious access behavior, but legacy tools cannot detect the pattern.
Undetected Exceptions
Traditional monitors rarely contextualize anomalous events, such as an API exception. They flag uptime issues but miss underlying logic failures, leaving teams to react to symptoms rather than causes.
This is why monitoring API errors the old way creates false confidence rather than real insight.
3. Why These Gaps Hurt the Business
When dashboards mislead, organizations:
- Respond late,
- Misdiagnose issues,
- Underestimate risk,
- And fail to prevent repeat incidents.
This isn’t just a technical visibility gap. It’s a business visibility gap, one that directly affects customer experience, security posture, and operational cost.
The next generation of API monitoring isn’t about collecting more logs or generating more alerts. It’s about interpreting signals, not just tracking them.
And that’s where the fundamental transformation begins: turning errors into intelligence.
From Noise to Narrative: How Smart Leaders Turn API Errors into Strategy
Most organizations treat API errors as clutter, something engineers fix and forget. But for modern leaders, those same errors have become one of the most valuable sources of business intelligence. Hidden inside each anomaly is insight about customer experience, system reliability, security posture, and operational risk.
The difference between reactive and strategic teams comes down to one shift: they stop treating API errors as noise and start treating them as signals.
Introducing the API Error Intelligence Hub
Imagine a single dashboard that collects, classifies, and ties every API anomaly across your stack directly to business outcomes. Not just logs. Not just alerts.
A true API Error Intelligence Hub shows:
- Which workflows are failing?
- Which customer journeys are breaking?
- Which partners or integrations are unstable?
- And what each error costs in revenue, trust, or SLA exposure.
This transforms API errors from scattered technical events into a map of system health your entire leadership team can understand.
Mature organizations already use such hubs in their weekly and quarterly business reviews. API behavior becomes part of performance strategy, not just engineering chatter.
How It Elevates Every Executive Role
CISO: Turning Error Patterns into Security Foresight
Error clusters expose more than failures. They reveal reconnaissance attempts, permission probing, and abnormal access behavior. A CISO who sees 401 spikes or odd permission errors can catch threats long before they turn into breaches.
CTO: A Real-Time Lens Into Performance and Scalability
For a CTO, errors highlight integration friction, dependency bottlenecks, and capacity constraints. Instead of guessing what to scale or optimize, decisions become evidence-driven.
CFO: Quantifying Risk in Real Time
API instability equals financial instability. A CFO can map:
- Dips in revenue,
- SLA penalties,
- Churn risk,
- And support costs
are directly related to error patterns.
For the first time, technical issues translate into measurable financial signals.
A Simple 3-Step Framework to Make This Real

1. Centralize Error Data
Bring logs, traces, and events into a single observability layer, whether via ELK, Datadog, Splunk, Grafana, or a platform like AppSentinels.
2. Contextualize by Business Process
Tie each error to the journey it affects: checkout, login, onboarding, payouts, partner integrations.
3. Correlate With Outcomes
Connect error spikes to business impact: revenue dips, user drop-offs, SLA risks, or trust metrics.
This is how raw anomalies become strategy.
Every API error is a post-it note from your digital nervous system – if you know how to read it.
Effective API error handling doesn’t stop at code fixes. It means translating anomalies into business intelligence. These rest api error-handling best practices evolve into governance models once tied to KPIs.
And when you start listening closely enough, you realize the next step isn’t just responding. It’s predicting.
Looking Ahead: The Evolution of API Intelligence
The API monitoring landscape is evolving rapidly. Organizations are moving beyond reactive alerting toward systems that can anticipate problems before they impact users.
The next generation of API intelligence will combine real-time detection with predictive capabilities. Machine learning models will analyze behavioral patterns to forecast potential failures hours or even days in advance. AI-assisted remediation will enable automated systems to take corrective actions, such as rerouting traffic, refreshing credentials, or isolating degraded services, without waiting for human intervention.
But prediction and automation are only valuable when they’re trustworthy. This is why Explainable AI (XAI) matters. The platforms leading this shift will pair automated remediation with transparent reasoning, showing teams exactly why decisions were made, which patterns triggered them, and how confident the system is in its actions. This keeps humans in control while reducing the operational burden of constant firefighting.
The goal is clear: environments where breaches are caught before data leaves the system, outages are prevented instead of managed, and teams spend more time innovating than responding to incidents.
The foundation for this future is being built today through behavioral baselining, anomaly detection, and automated response systems. Organizations that invest in intelligent API observability now will be best positioned to adopt AI-assisted remediation and explainable AI capabilities as they mature.
Prediction will become the new prevention. But it starts with visibility, understanding, and a leadership culture that treats API health as a strategic priority.
Frequently Asked Questions on API Errors
Even seasoned executives have questions about understanding API errors at a strategic level. Here are clear, human explanations to the questions that come up most often in boardrooms, architecture reviews, and incident retrospectives.
1. What’s the difference between an API error and an API failure?
An API error is a single faulty event: a bad request, a timeout, a permission mismatch, or an internal server issue. An API failure occurs when multiple errors accumulate or persist long enough to break a workflow, disrupt a customer journey, or take a system offline.
Think of it this way:
- Error = a symptom
- Failure = when symptoms cluster into a breakdown
Leaders should track both.
2. Can API errors lead to data breaches?
Yes, and they often do.
API errors can:
- Expose internal logic or sensitive metadata,
- Reveal authentication weaknesses,
- Leak internal endpoints,
- Or show attackers exactly where validation is weak.
A simple error pattern around authentication endpoints can serve as a map for attackers probing for weaknesses.
3. How can we tell if errors are developer bugs or integration issues?
The fastest way is to look at where and how the error appears:
- 4xx errors usually come from client-side bugs, bad inputs, or misaligned contracts.
- 5xx errors typically reflect backend or infrastructure issues.
- Timeouts and dependency failures almost always indicate integration or ecosystem problems.
Modern API observability platforms make this distinction clear by correlating:
- Service-level logs,
- Dependency traces,
- And affected business processes.
Instead of guessing, teams see exactly which system (or integration) broke the chain.
4. What’s the ROI of API observability?
Leaders usually see returns in four areas:
- Revenue protection: fewer failed transactions and drop-offs
- Cost savings: reduced firefighting and support overhead
- Security posture: early detection of suspicious behavior
- Customer experience: smoother checkouts, logins, and integrations
Many enterprises pay for observability within months simply by preventing a single outage or catching a misconfiguration early.
5. What’s the role of AI in preventing API errors?
AI is reshaping reliability from reactive to predictive. It can:
- Detect early warning signals in error patterns,
- Forecast outages before users feel them,
- Auto-reroute traffic around failing services,
- Auto-refresh tokens or credentials,
- And even roll back unstable deployments.
The future of error prevention isn’t alerts. It’s anticipation and self-healing. Human oversight stays central, but AI now carries the operational load.
The Leadership Imperative: Making API Health a Board-Level Metric
APIs have quietly become the infrastructure that runs the modern enterprise. Payments, logins, integrations, partner workflows, analytics: everything flows through them. Which means API health isn’t an engineering metric anymore. It’s a business metric that belongs on the same dashboard as revenue, churn, and customer satisfaction.
API Health Is Now a KPI
Every reliable API reinforces your brand promise. Every broken API undermines it.
Leaders who track API stability alongside financial and customer metrics gain a clearer view of the organization’s real-time health. API performance signals:
- User friction,
- Security vulnerabilities,
- Operational stress,
- And revenue exposure.
It’s the closest thing to a digital vital sign that modern businesses have.
Why This Requires Cross-Functional Governance
API stability can’t live solely in engineering. It affects:
- Security teams, who see errors as early threat intelligence
- Product teams that rely on healthy APIs for seamless experiences
- Finance teams, who feel the cost of downtime and SLA breaches
- Business leaders who need predictable performance across all workflows
When these groups govern API health together, reliability becomes a shared responsibility rather than a siloed firefight.
The Forward Look: What Smart Leaders Already Understand
The most resilient organizations treat error visibility as a strategic posture, not operational hygiene. They don’t wait for customers to complain. They don’t let breaches originate from misconfigured endpoints. They don’t allow silent timeouts to bleed revenue unnoticed.
They listen early. They interpret often. They treat every anomaly as insight.
APIs run your business. Errors reveal their truth. The most innovative leaders are already listening.
And for enterprises that want to turn that truth into resilience rather than risk, one thing is clear:
AppSentinels helps teams transform API telemetry into foresight, building systems that predict, protect, and perform.